0x08.保护机制
与一般的程序相同,Linux Kernel同样有着各种各样的保护机制:
一、通用保护机制
KASLR
KASLR即内核空间地址随机化(kernel address space layout randomize),与用户态程序的ASLR相类似——在内核镜像映射到实际的地址空间时加上一个偏移值,但是内核内部的相对偏移其实还是不变的
在未开启KASLR保护机制时,内核代码段的基址为 0xffffffff81000000 ,direct mapping area 的基址为 0xffff888000000000
内核内存布局可以参考这↑里↓
*FGKASLR
KASLR 虽然在一定程度上能够缓解攻击,但是若是攻击者通过一些信息泄露漏洞获取到内核中的某个地址,仍能够直接得知内核加载地址偏移从而得知整个内核地址布局,因此有研究者基于 KASLR 实现了 FGKASLR,以函数粒度重新排布内核代码
STACK PROTECTOR
类似于用户态程序的 canary,通常又被称作是 stack cookie,用以检测是否发生内核堆栈溢出,若是发生内核堆栈溢出则会产生 kernel panic
内核中的 canary 的值通常取自 gs 段寄存器某个固定偏移处的值
SMAP/SMEP
SMAP即管理模式访问保护(Supervisor Mode Access Prevention),SMEP即管理模式执行保护(Supervisor Mode Execution Prevention),这两种保护通常是同时开启的,用以阻止内核空间直接访问/执行用户空间的数据,完全地将内核空间与用户空间相分隔开,用以防范ret2usr(return-to-user,将内核空间的指令指针重定向至用户空间上构造好的提权代码)攻击
SMEP保护的绕过有以下两种方式:
- 利用内核线性映射区对物理地址空间的完整映射,找到用户空间对应页框的内核空间地址,利用该内核地址完成对用户空间的访问(即一个内核空间地址与一个用户空间地址映射到了同一个页框上),这种攻击手法称为 ret2dir
- Intel下系统根据CR4控制寄存器的第20位标识是否开启SMEP保护(1为开启,0为关闭),若是能够通过kernel ROP改变CR4寄存器的值便能够关闭SMEP保护,完成SMEP-bypass,接下来就能够重新进行 ret2usr,但对于开启了 KPTI 的内核而言,内核页表的用户地址空间无执行权限,这使得 ret2usr 彻底成为过去式
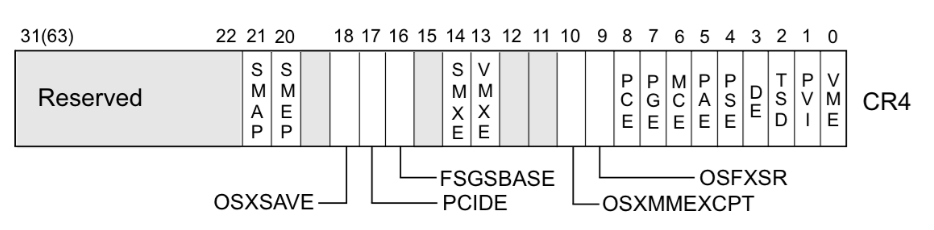
在 ARM 下有一种类似的保护叫
PXN
KPTI
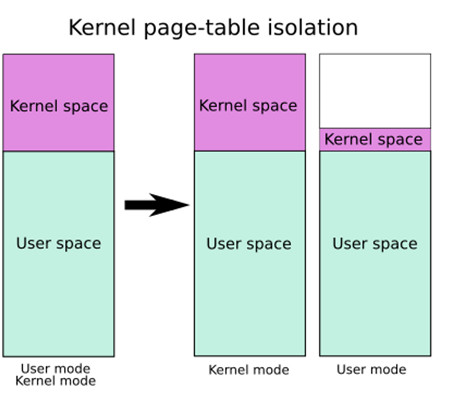
KPTI即内核页表隔离(Kernel page-table isolation),内核空间与用户空间分别使用两组不同的页表集,这对于内核的内存管理产生了根本性的变化
需要进行说明的是,在这两张页表上都有着对用户内存空间的完整映射,但在用户页表中只映射了少量的内核代码(例如系统调用入口点、中断处理等),而只有在内核页表中才有着对内核内存空间的完整映射,但两张页表都有着对用户内存空间的完整映射,如下图所示,左侧是未开启 KPTI 后的页表布局,右侧是开启了 KPTI 后的页表布局
在 64 位下用户空间与内核空间都占 128 TB,所以他们占用的页全局表项(PGD)的大小应当是相同的,图上没有体现出来,因此这里由笔者代为补充(笑)
KPTI 的发明主要是用来修复一个史诗级别的 CPU 硬件漏洞:Meltdown。简单理解就是利用 CPU 流水线设计中(乱序执行与预测执行)的漏洞来获取到用户态无法访问的内核空间的数据,属于侧信道攻击的一种
简单理解:你的第一条指令是合法内存访问,第二条指令是越权内存访问,CPU会在执行第一条正常指令的过程中也会执行第二条非法指令,之后再做权限判定,若是非法访问则消除该影响,这样的流水线设计虽然有着较高的性能,但是越权访问仍会留下痕迹,这给了攻击者非法获取内核空间数据的可能
若是整个流水线设计直接扔掉那自然是捡了芝麻丢了西瓜,因此 KPTI 被快速应用到主流操作系统上(这个设计在漏洞出来之前就有,但未得到广泛应用),尽管仍旧造成了一定的性能损耗,但却有效地从软件层面修复了 Meltdown 漏洞
KPTI 同时还令内核页表中属于用户地址空间的部分不再拥有执行权限,这使得 ret2usr 彻底成为过去式
二、内核“堆”上保护机制
more info 可以参考这里
Hardened Usercopy
hardened usercopy 是用以在用户空间与内核空间之间拷贝数据时进行越界检查的一种防护机制,主要检查拷贝过程中对内核空间中数据的读写是否会越界:
- 读取的数据长度是否超出源 object 范围
- 写入的数据长度是否超出目的 object 范围
不过这种保护 不适用于内核空间内的数据拷贝 ,这也是目前主流的绕过手段
这一保护被用于 copy_to_user() 与 copy_from_user() 等数据交换 API 中
Hardened freelist
类似于 glibc 2.32 版本引入的保护,在开启这种保护之前,slub 中的 free object 的 next 指针直接存放着 next free object 的地址,攻击者可以通过读取 freelist 泄露出内核线性映射区的地址,在开启了该保护之后 free object 的 next 指针存放的是由以下三个值进行异或操作后的值:
- 当前 free object 的地址
- 下一个 free object 的地址
- 由 kmem_cache 指定的一个 random 值
攻击者至少需要获取到第一与第三个值才能篡改 freelist,这无疑为对 freelist 的直接利用增添不少难度
在更新版本的 Linux kernel 中似乎还引入了一个偏移值,笔者尚未进行考证
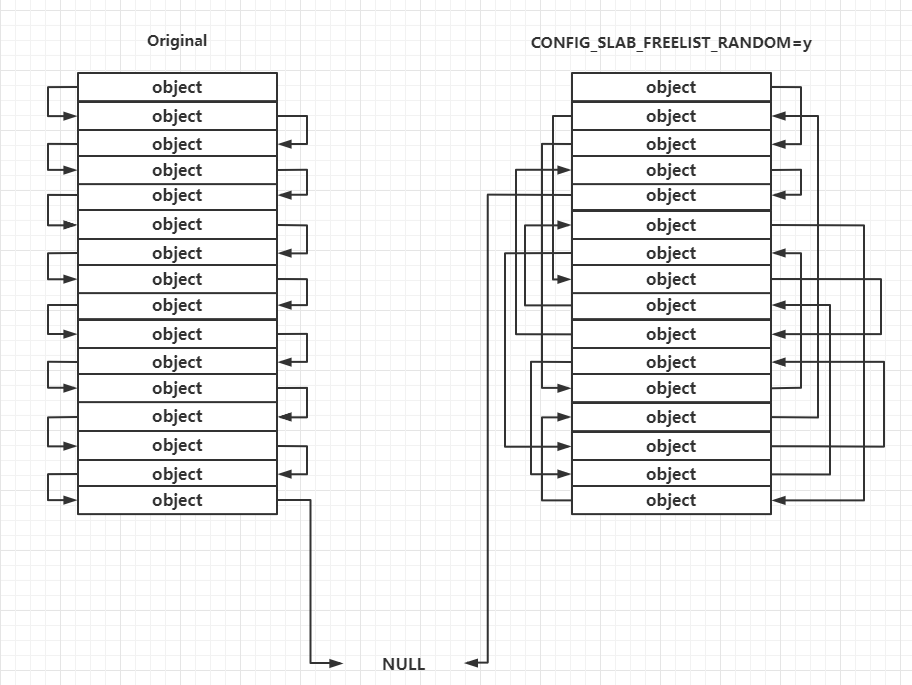
Random freelist
这种保护主要发生在 slub allocator 向 buddy system 申请到页框之后的处理过程中,对于未开启这种保护的一张完整的 slub,其上的 object 的连接顺序是线性连续的,但在开启了这种保护之后其上的 object 之间的连接顺序是随机的,这让攻击者无法直接预测下一个分配的 object 的地址
需要注意的是这种保护发生在slub allocator 刚从 buddy system 拿到新 slub 的时候,运行时 freelist 的构成仍遵循 LIFO
CONFIG_INIT_ON_ALLOC_DEFAULT_ON
当编译内核时开启了这个选项时,在内核进行“堆内存”分配时(包括 buddy system 和 slab allocator),会将被分配的内存上的内容进行清零,从而防止了利用未初始化内存进行数据泄露的情况
据悉性能损耗在 1%~7% 之间