0x02. 内存管理
内存管理是操作系统最核心的一部份之一,不可不品尝
一、物理内存管理
内核地址空间布局
首先来一张 64 位 NT kernel 内存布局总览:
32 位就暂时不考虑研究了,毕竟从 Win11 开始就已经都是纯 64 位了
| Start | End | Size | Description | Usage |
|---|---|---|---|---|
| FFFF080000000000 | FFFFF67FFFFFFFFF | 238TB | Unused System Space | 不会被用到的空间 |
| FFFFF68000000000 | FFFFF6FFFFFFFFFF | 512GB | PTE Space | 页表所在区域 |
| FFFFF70000000000 | FFFFF77FFFFFFFFF | 512GB | HyperSpace | 用来做临时中转映射 |
| FFFFF78000000000 | FFFFF78000000FFF | 4K | Shared System Page | 共享内存空间,(作为内核入口点?)在每个进程中都有映射 |
| FFFFF78000001000 | FFFFF7FFFFFFFFFF | 512GB-4K | System Cache Working Set | 系统缓存的工作集 |
| FFFFF80000000000 | FFFFF87FFFFFFFFF | 512GB | Initial Loader Mappings | 最初的内核加载器所用区域 |
| FFFFF88000000000 | FFFFF89FFFFFFFFF | 128GB | Sys PTEs | 系统页表项区域,MDL 映射的虚拟内存和驱动映像都在此处 |
| FFFFF8a000000000 | FFFFF8bFFFFFFFFF | 128GB | Paged Pool Area | 分页内存区域 |
| FFFFF90000000000 | FFFFF97FFFFFFFFF | 512GB | Session Space | 会话空间 |
| FFFFF98000000000 | FFFFFa70FFFFFFFF | 1TB | Dynamic Kernel VA Space | 动态内存区域 |
| FFFFFa8000000000 | *nt!MmNonPagedPoolStart-1 | 6TB Max | PFN Database | 存储 PFN 相关信息 |
| *nt!MmNonPagedPoolStart | *nt!MmNonPagedPoolEnd | 512GB Max | Non-Paged Pool | 非分页内存区域(不会被换到硬盘上) |
| FFFFFFFFFFc00000 | FFFFFFFFFFFFFFFF | 4MB | HAL and Loader Mappings | 硬件抽象层与加载器所用区域 |
_MMPFN:物理页框
类似于 Linux kernel 中使用 page 结构体数组表示物理内存的方式,在 NT kernel 中使用 _MMPFN 结构体来表示一张物理页,并通过一个结构体数组来管理所有的物理内存页,数组下标即为物理页的页帧号(Page Frame Number,PFN),该数组即为 PFN Database 区域,在全局指针变量 _MMPFN* MmPfnDatabase 中存放着该数组的地址:
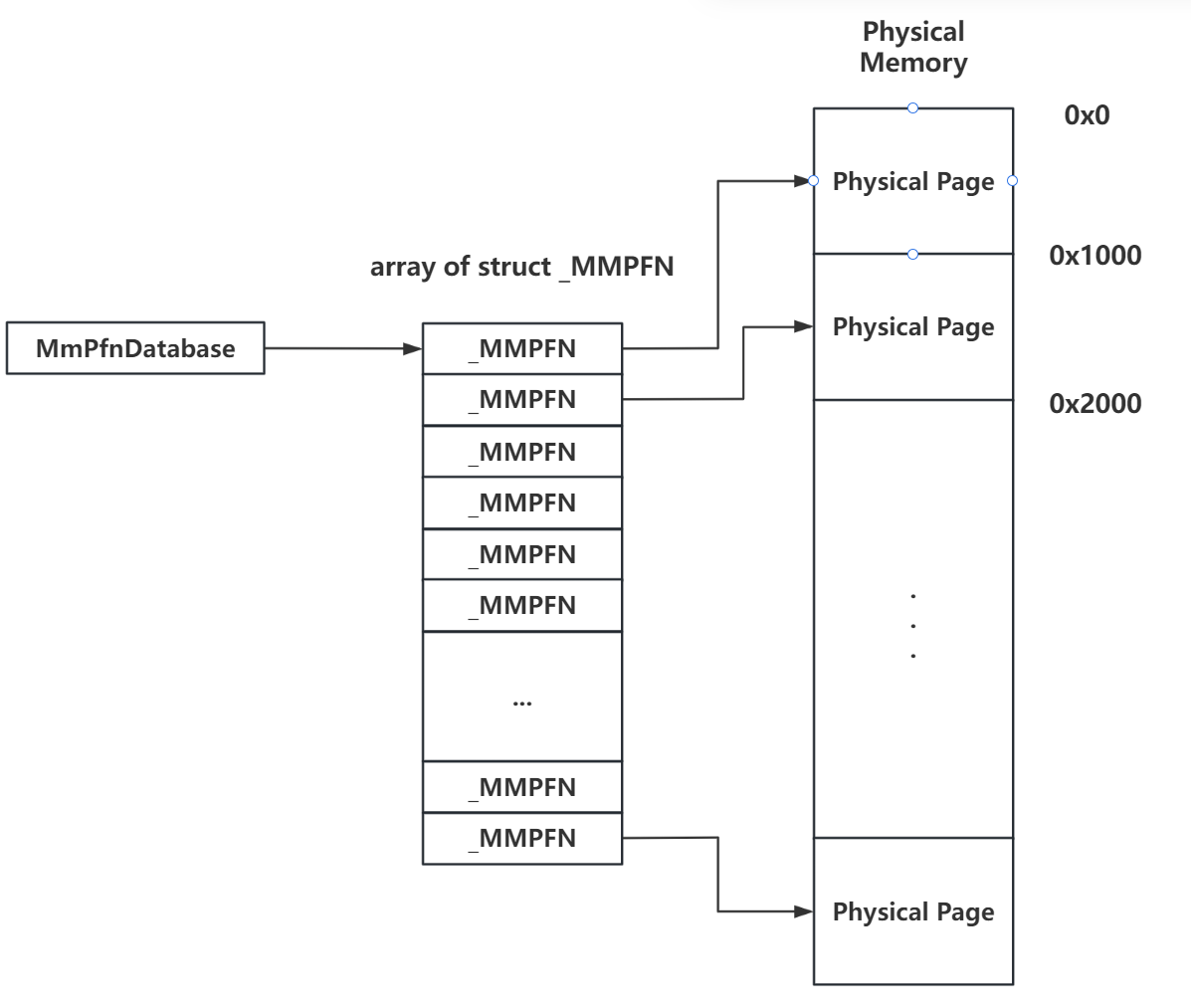
根据 Page 的不同用途,非 active 页面对应的_MMPFN 会被放入不同的链表当中,链表头为 _MMPFNLIST 结构体:
MmZeroedPageListHead:清零了的空闲页面链表MmFreePageListHead:常规空闲页面链表,系统空闲时会从中取出页面进行清零后放到MmZeroedPageListHead上MmStandbyPageListHead:进程从其工作集(working set,即进程的虚拟地址空间中驻留在物理内存中的一组页面)中丢弃页面时,若页未被修改则放入该链表,在 free 链表和 zeroed 链表都为空时会从上分配页面MmModifiedPageListHead:进程从其工作集中丢弃页面时,若页被修改且需要写回磁盘则放入该链表,在 modified page writer 完成操作之后会将页面放至 standby 链表MmModifiedNoWritePageListHead:进程从其工作集中丢弃页面时,若页被修改且不需要写回磁盘则放入该链表,modified page writer 完成操作之后会将页面放至 standby 链表MmBadPageListHead:这些页面可能存在一些故障
进程从其工作集中丢弃页面有两种原因,一是原有工作集已满且要引入新页面,二是内存管理器修剪了其工作集(例如内存不够用了)
在进程退出时,所有的页面都会进入 freepagelist 链表中
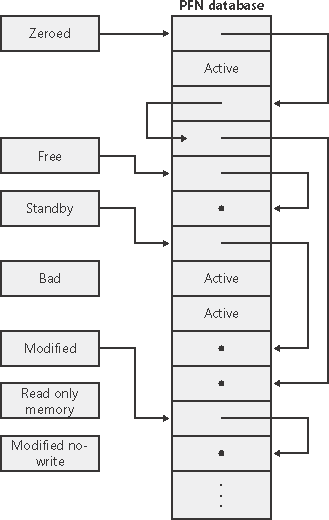
页面在不同链表间循环的总览图如下:
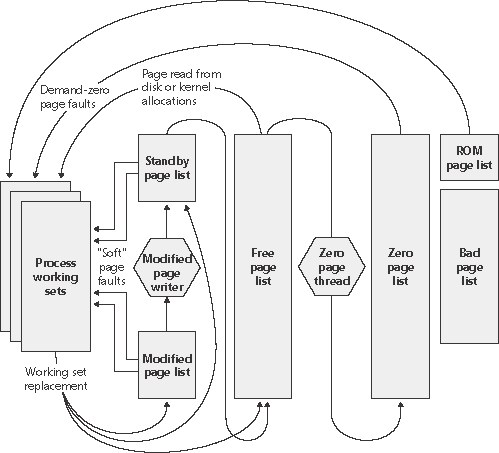
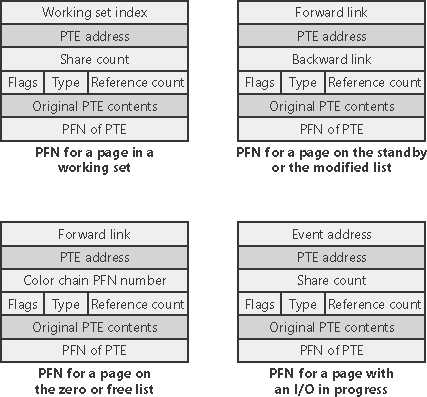
在 _MMPFN 结构体当中同样用了大量的 union,当页面在不同链表间循环时, _MMPFN 不同偏移的字段有着不同含义:
二、Pool Memory(before 19H1)
Windows NT kernel 将页面按照不同的用途分为不同的“池”(Pool)来管理,并将这些页面划分为更细粒度的小对象供内核组件使用,池的总类一共有三种:
- 非换页池(Non Paged Pool):该池中的页面常驻物理内存中,不会被换出到磁盘
- 换页池(Paged Pool):该池中的页面在内存紧张时可能被换出到磁盘
- 会话换页池(Session Paged Pool):该池中的页面在内存紧张时可能被换出到磁盘,不同会话间存在隔离
基本单位:池块(Pool Block)
池内存中每次内存分配的对象称为一个池块(Pool Block),类似于 ptmalloc2 中的 chunk,每个池块的数据前部有一个 header 存储如下数据:
- Previous Size:相邻低地址池块的大小右移 4 位的结果
- Pool Index:池块归属的池描述符组的索引,多个池描述符组成一个池描述符数组
- Block Size:池块大小右移 4 位的结果
- Pool Type:池块所属池的类型
- Pool Tag:调试时用于进行识别的字符
- (一个Union):
- Process Billed:指向分配了这个池块的进程描述符
_EPROCESS的指针 - (一个结构体)
- Allocator Back Trace Index:
- Pool Tag Hash:
- Process Billed:指向分配了这个池块的进程描述符
此外,自 Windows Server 2003 版本起,在 Pool Chunk 尾部引入了 Canary 字段,用于预防潜在的 chunk overflow,这个值会在 ( 暂时没查到更多信息,推测是池块分配与释放时 ) 时被检查
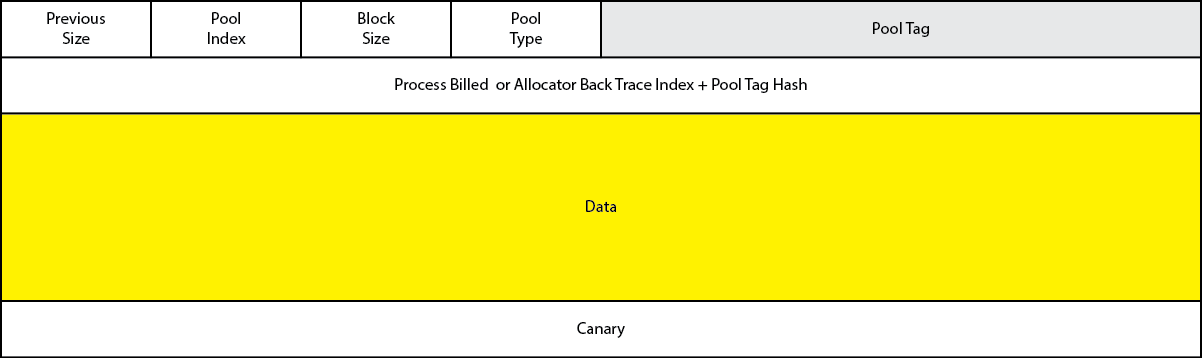
需要注意的是,Pool Chunk 仅用于请求内存大小不大于 4080 字节的情况(加上 16 字节的 header 刚好一张内存页大小)
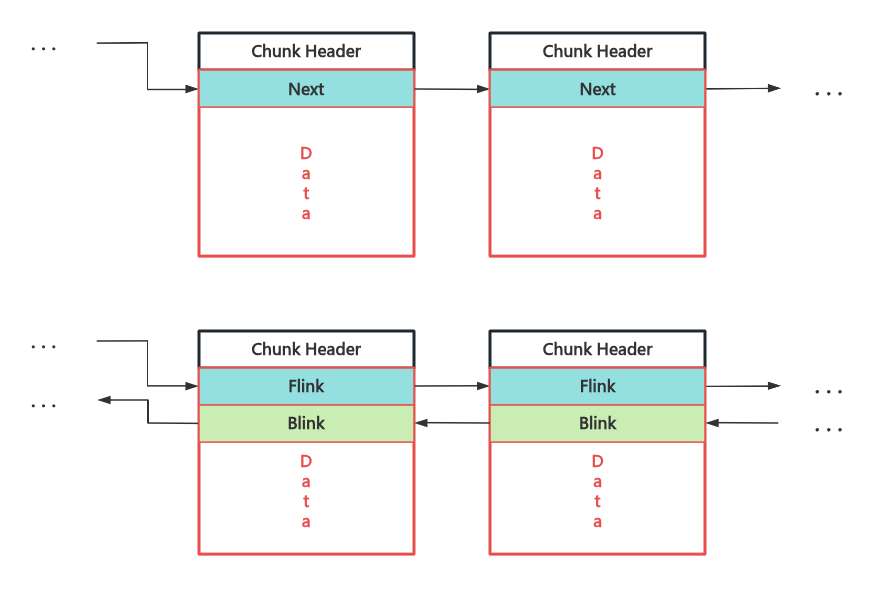
Pool Chunk 的管理与 ptmalloc2 chunk 非常相似,在 NT kernel 中会复用 Freed Chunk 的 Data 字段来组织 Free Chunk 为单向或双向链表:
池描述符:内核共享内存池
这个结构在 Windows 10 数个版本当中也经历了一定的大大小小的变化,
搞得👴很头疼,但比较关键的变化是从 1809 版本到 1903 (19H1)版本,自 1903 版本 NT kernel 引入了 Segment Heap 机制作为内核的动态内存分配器,因此这一小节我们主要讲 1809 及以前的仍使用池内存分配器的 64 位版本
类似于 Linux kernel 中的 kmem_cache ,Windows kernel 中单个内存池使用 _POOL_DESCRIPTOR 结构进行表示,其结构如下图所示:
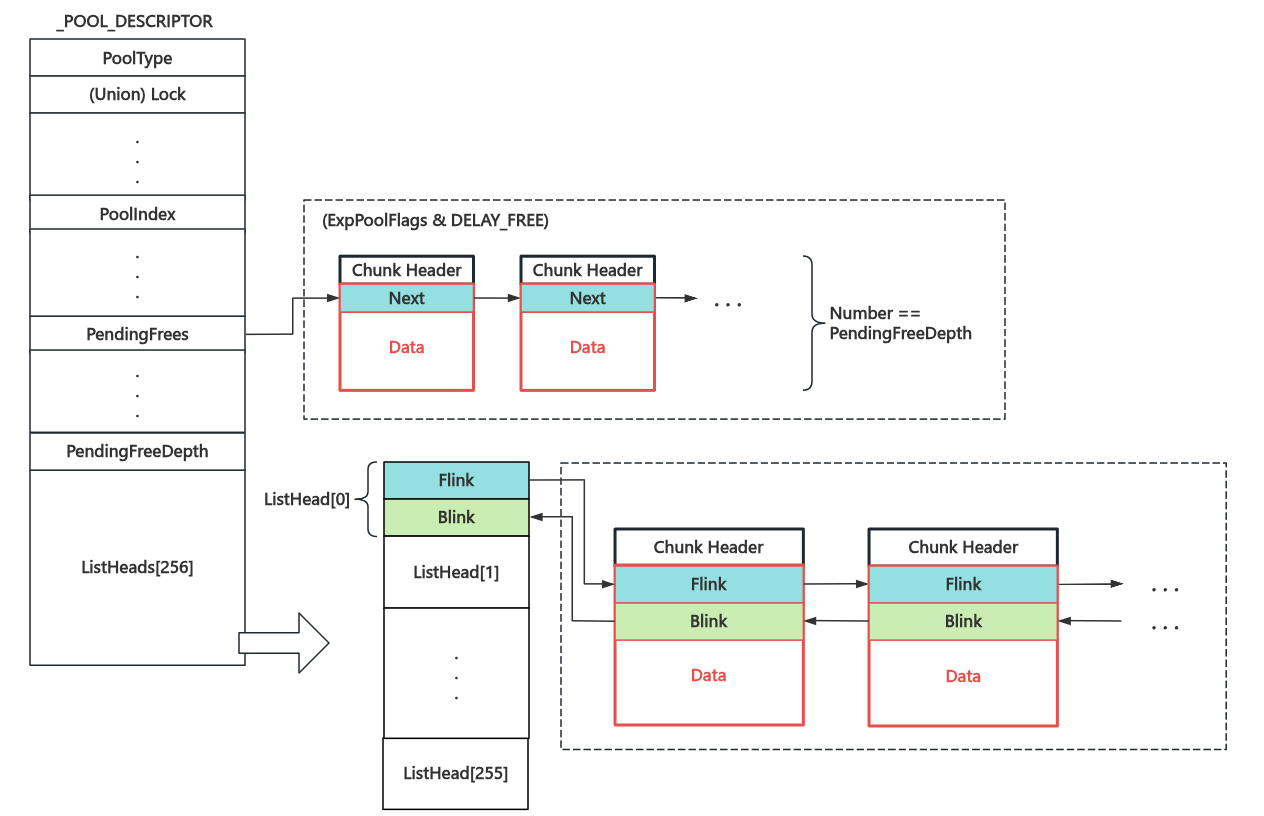
池描述符所对应的内存池在整个内核间共享,比较核心的有两个链表:
- ListHeads 链表数组:存放常规的释放后的池块,使用双向链表进行连接,根据池块大小的不同放入不同的子链表中
- PendingFrees 链表:当内存池设置了
DELAY_FREE标志位时,池块释放后会先链入该单向链表(大小不限),当链表深度超过指定值时再统一回收
所有初始的内存池描述符都放在 nt!PoolVector 数组当中
核心独占内存池:Lookaside Lists
池描述符对应的内存池在所有核心间共享,核心一多效率就灾难了,因此每个核心实际上还有一个独有的内存池,存放在内核态 GS 寄存器指向的 处理器控制区(Process Control Region,为 _KPCR 结构体,类似于 Linux 下的 .percpu 段)当中—— Lookaside Lists 用于优先处理当前核心的池内存请求,只有当其不足以满足需求时才会向共享内存池请求内存
LookasideList 的结构如下图所示,根据大小归属数组上不同的链表,每个链表又分为二个子链:一个单向链表(默认,长度有上限,LIFO)与一个双向链表(前者满时放到这),LookasideList 的数组成员数量较少因此仅用于较小的内存分配
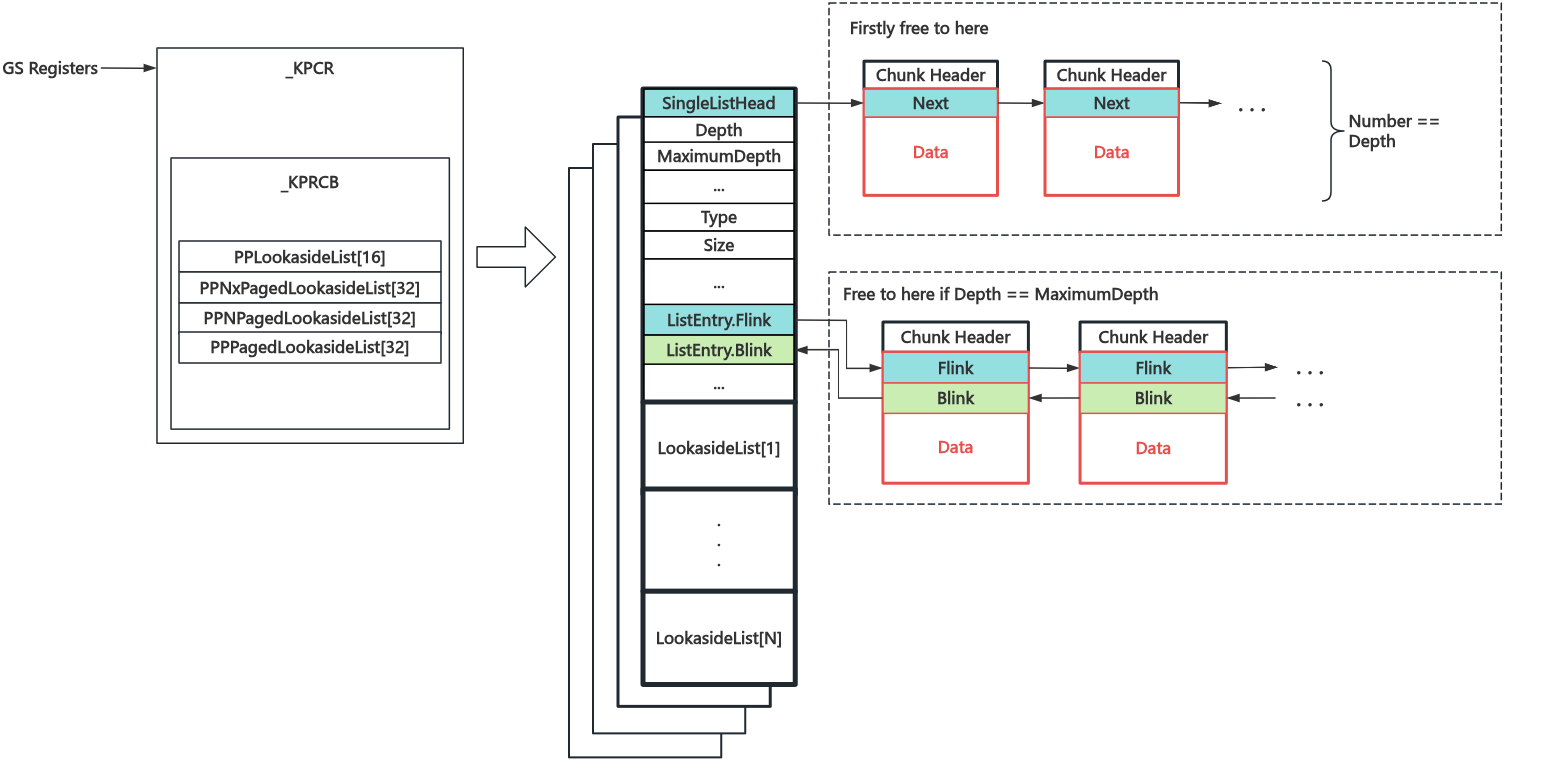
LookasideList 一共有四类(PP == Per Processsor):
- PPLookasideList:用于频繁分配与释放的对象的 LookasideList
- PPNxPagedLookasideList:非换页池的 non-eXecuted 页面的 LookasideList
- PPNPagedLookasideList:非换页池的 LookasideList
- PPPagedLookasideList:换页池的 LookasideList
PPLookasideList 和其他 LookasideList 有什么不同?笔者也不知道
,静待 Windows 开源的那一天......
内存分配基本算法
1️⃣ 内存请求顺序
池内存的分配核心函数是 ExAllocatePoolWithTag(POOL_TYPE PoolType,SIZE_T NumberOfBytes,ULONG Tag) ,用户需要手动指定分配的池类型、需要的内存大小等信息,内核组件与驱动通常通过该 API 或是更上层的 Wrapper 完成内核中的内存分配请求
- 通用的池内存分配仅适用于小于 4080 字节的内存请求,对于大于这个大小的内存请求则内部会通过
nt!ExpAllocateBigPool()完成 - 首先会尝试根据请求的池类型从
_KPCR的 LookasideList 区域的不同链表进行内存分配,如果可以满足则直接返回 - 若 LookasideList 无法满足,锁上对应的池,并尝试从 ListHeads 链表进行分配,若分配的池块大小大于所需则会将其分割为两块,一块返回给用户一块挂回 ListHeads 链表
- 若无可用池块,则会调用
nt!MiAllocatePoolPages分配内存页,并将其分割为两块,一块返回给用户一块挂回 ListHeads 链表
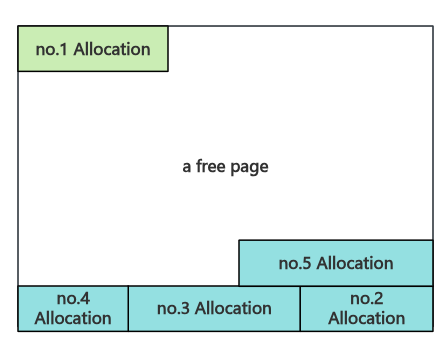
2️⃣ 池块分割方法:非页对齐的块从尾部分割
在分割池块时,内核首先会检查池块的地址,若与内存页大小对齐(0x1000)则从头部分割出用户所需的池块,否则从尾部分割下用户所需的池块
内存释放基本算法
池内存的释放核心函数是 ExFreePoolWithTag(PVOID Entry, ULONG Tag) ,内核组件与驱动通常通过该 API 或是更上层的 Wrapper 完成内核中的内存释放请求
在 Chunk header 当中存放着该 Chunk 所属的 Pool Type & Index,因此释放时可以直接判断归属的 Pool 与对应的 List,具体释放流程如下:
- 首先检查该 Chunk 是否为页的第一个 Chunk (页对齐),若是则尝试调用
nt!MiFreePoolPages()进行回收,成功则直接返回 - 接下来检查物理相邻高地址 Chunk 的 PrevSize 是否与该 Chunk header 记录的 Size 相等,若否会报错
- 如果 Size 小于某个特定值,尝试放回相应的 Lookaside List 中
- 如果对应的 Pool 设置了
DELAY_FREE标志位,放回 PendingFrees List(如果PendingFreeDepth 大于某个特定值,会先调用nt!ExDeferredFreePool函数清空 PendingFrees List) - 检查相邻低地址、高地址 Chunk 状态,合并空闲块,需要注意这里 不会与下一张内存页的头部 Chunk 合并
- 最后检查该 Chunk 所在 Page 是否为空闲页,若是则调用
nt!MiFreePoolPages()进行回收,否则放回对应的 ListHeads 链表
说实话笔者比较疑惑第一步为什么这么设计,因为在笔者看来似乎 mismatch 的概率会很大,那这不就平白有性能损失了。。。
三、Segment Heap in Kernel(from 19H1)(🕊)
自 NT kernel 19H1 版本起,用户态 Segment Heap 的分配逻辑被引入内核,